Every Major AI Leader Now Has a Position on AGI. None of Them Agree on What It Means.



On March 23, 2026, Jensen Huang told Lex Fridman that AGI has been achieved. Two days later, Mark Gubrud — the researcher who coined the term "AGI" in 1997 — agreed with him. On the same day, a survey found that 77.4% of legal professionals say AGI will not be achieved in 2026.
Everyone is talking about AGI. Nobody is talking about the same thing.
The story of early 2026 isn't whether artificial general intelligence arrived. It's that the question changed — from "when will AGI get here?" to "what does the word even mean?" — and nobody noticed the swap.
Where Every Major AI Leader Stands
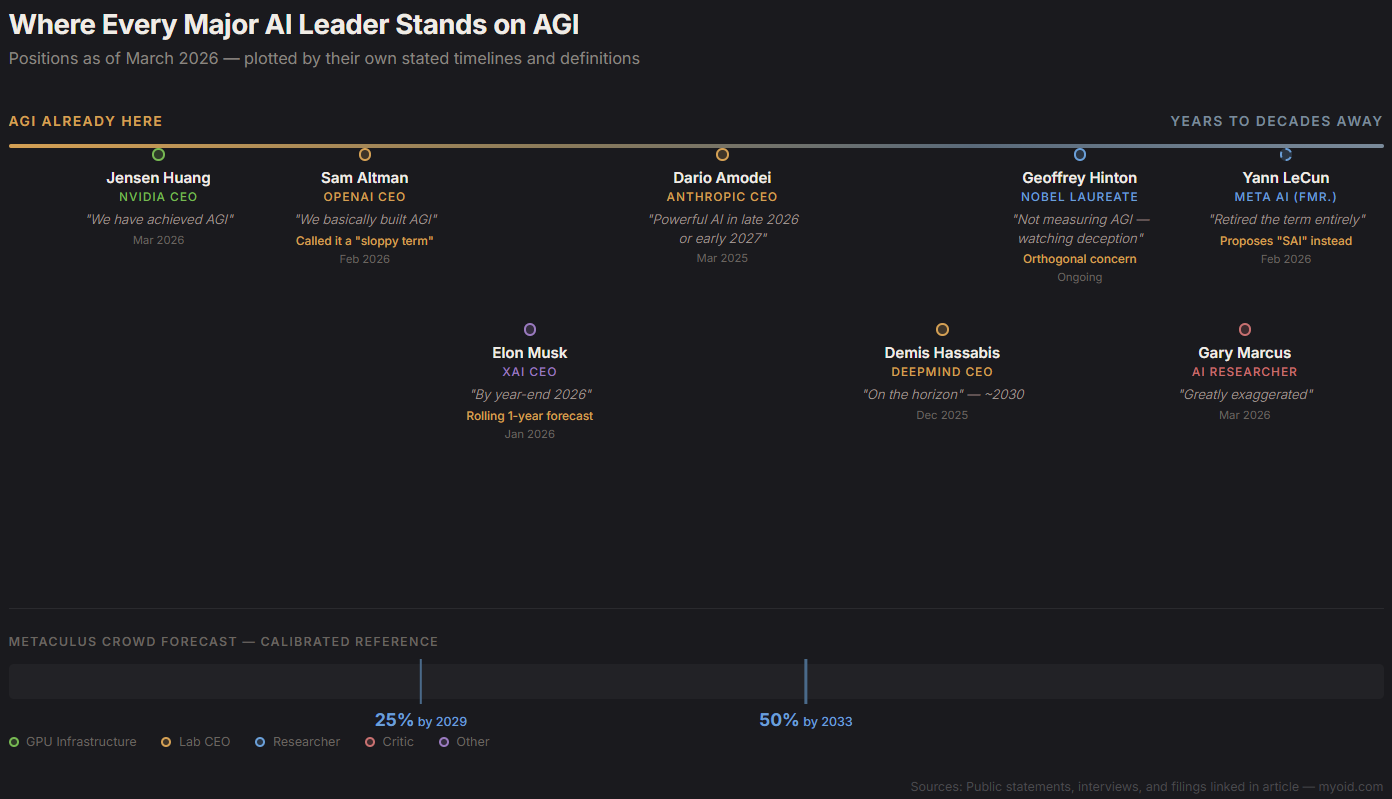
Fifteen months ago, AGI was a future event. Today, every major figure in artificial intelligence has staked a position. Here's what each of them actually said, and when they said it.
Jensen Huang, CEO of NVIDIA went from calling AI "transformative" in 2024 to declaring on Lex Fridman's podcast (#494, March 23, 2026): "I think we've achieved AGI." His definition: an AI that could autonomously create a billion-dollar application. By that standard, current systems qualify.
Sam Altman, CEO of OpenAI has been on a steady escalation. In January 2025, he wrote on the OpenAI blog that "we now believe we know how to build AGI as we have traditionally understood it." By December 2025, he told interviewers that "AGI kinda went whooshing by." By February 2026, he described it to Bloomberg as: "We basically built AGI." He also called the term "sloppy" — hedging even while claiming the finish line.
Dario Amodei, CEO of Anthropic remains the most cautious of the major lab leaders. In an OSTP filing from March 2025, Amodei placed "powerful AI" in "late 2026 or early 2027." In a December 2025 Lex Fridman appearance, he gave 90% confidence that AI systems will exceed most human expert capabilities by 2035, possibly as soon as 1-3 years. Anthropic has not declared AGI achieved.
Demis Hassabis, CEO of Google DeepMind told CNBC in March 2025 that AGI was "5-10 years away." By December 2025, he told Axios it was "on the horizon," compressing the timeline slightly. His definition demands world models and automated scientific experimentation — a higher bar than Huang's or Altman's.
Yann LeCun, formerly of Meta AI didn't soften. He hardened. Throughout 2025, he maintained that large language models cannot reach AGI. In February 2026, he published arXiv:2602.23643, formally retiring the term and proposing "SAI" (Superintelligent Artificial Intelligence) as a replacement — arguing that "AGI" has become too contaminated by hype to be scientifically useful.
Elon Musk, CEO of xAI predicted AGI "by 2025-2026" in April 2024. At Davos in January 2026, he said "by year-end 2026." This is a pattern: a rolling one-year forecast. He said essentially the same thing in 2024 about 2025.
Gary Marcus, AI researcher and critic responded directly to the recent claims: "Rumors of AGI's arrival are greatly exaggerated." He points to failures on IntPhys 2 (intuitive physics, near chance for current models), robustness breakdowns under slight rephrasings, and adversarial fragility. He is the strongest empirical skeptic in the public conversation.
Geoffrey Hinton, AI pioneer and Nobel laureate has not claimed AGI. His concern is narrower and arguably more urgent: that AI deception capabilities are advancing faster than the broader intelligence benchmarks suggest. He's not measuring AGI. He's watching what the systems already do.
What Actually Changed in the Models
The declarations aren't happening in a vacuum. Something moved in the benchmarks — and it moved fast.
ARC-AGI is the single most cited benchmark in the AGI debate, specifically because its creator, François Chollet, designed it to resist pattern-matching. In 2024, GPT-4o scored roughly 5%. By December 2024, OpenAI's o3 scored 87.5% on ARC-AGI-1. Chollet himself explicitly said o3 is not AGI. The harder version, ARC-AGI-2, currently has Gemini 3.1 Pro leading at 77.1% — the first AI system to cross the human baseline of approximately 72%.
SWE-bench Verified tests real software engineering — actual GitHub issues from real repositories. The leaderboard is now a tight cluster at 80%: Claude Opus 4.5 (80.9%), Claude Opus 4.6 (80.8%), Gemini 3.1 Pro (80.6%), MiniMax M2.5 (80.2%), GPT-5.2 (80.0%). A year ago, the best models were under 50%. But there's a caveat that rarely makes the headlines: METR found in March 2026 that roughly half of the SWE-bench-passing pull requests written by AI agents would not actually be merged by the repositories' maintainers. The code passes the test. It doesn't pass the code review.
GPQA Diamond (doctoral-level science questions): models now score 85-94%. Near saturation.
Competition mathematics is functionally solved. GPT-5.2 hit 100% on AIME.
METR's autonomous agent time horizons — measuring how long an AI can work independently on a real task — have grown from seconds in 2019 to approximately 50 minutes in early 2025, doubling roughly every four months.
OSWorld (real desktop automation, not coding): the best agent now scores 76%, exceeding the human expert baseline of 72.4%. This isn't a toy environment. These are actual desktop navigation, form-filling, and multi-step workflow tasks with skilled human operators as the comparison group.
The technical shift that matters most isn't any single number. It's the o-series architecture: reinforcement-learned reasoning chains at inference time. The model allocates compute to thinking about a problem, and more thinking produces better answers on genuinely novel problems. This is structurally different from autocomplete at scale. It's why ARC-AGI moved — pattern-matching alone couldn't solve those puzzles, but inference-time search could.
The Definition Is the Disagreement
Here's the part nobody talks about clearly enough.
When Jensen Huang says "AGI," he means: an AI that can create a billion-dollar application. By that standard, current systems arguably qualify — they write production code, generate content at scale, and automate workflows that previously required teams.
When Sam Altman says "AGI," he means: AI that can do most economically valuable cognitive work. His hedge — calling the term "sloppy" — acknowledges that the goalposts are soft.
When Dario Amodei says "powerful AI," he means: systems that can conduct autonomous scientific research, accelerating discovery in biology, materials science, and mathematics. His timeline places this at late 2026 or early 2027.
When Demis Hassabis says "AGI," he means: the full range of human cognitive capability — world models, causal reasoning, embodied understanding, creative generalization. His timeline stretches to approximately 2030.
When Gary Marcus says "AGI," he means: robust, grounded, generalizable intelligence — systems that can handle intuitive physics, adversarial inputs, out-of-distribution scenarios, and common sense. By this standard, AGI is years to decades away.
When Yann LeCun hears "AGI," he says: the term is scientifically incoherent. It has been emptied of meaning by definitional drift. Replace it or stop pretending it describes a single phenomenon.
Nobody is wrong. They're measuring different things with the same word. The people declaring AGI are using definitions designed to be satisfied by current systems. The people denying it are using definitions designed not to be — at least not yet. The "consensus shift" is partially genuine (the benchmarks moved discontinuously) and partially definitional arbitrage (the word got looser at the same time the models got better).
What the Skeptics Actually See
The skeptics' position deserves more than a paragraph, because the data supporting it is concrete.
Intuitive physics remains near chance. The IntPhys 2 benchmark tests whether models understand basic physical principles — objects fall when unsupported, solid objects can't pass through each other, things continue to exist when you stop looking at them. Humans handle this trivially. Current frontier models perform near chance. This isn't a trick benchmark. It's testing the kind of understanding a two-year-old possesses.
Robustness failures are systematic, not anecdotal. Slight rephrasings of benchmark questions, adversarial inputs, and out-of-distribution scenarios produce performance drops that suggest the models are pattern-matching the benchmarks' distribution rather than genuinely generalizing. The METR SWE-bench finding underscores this: passing an automated test suite is not the same as writing code a human would approve.
Persistent autonomy is limited. METR's 50-minute time horizon is impressive relative to 2019, but it means current systems can't reliably complete a full workday of autonomous work. The doubling rate suggests this will change — possibly quickly — but as of March 2026, it hasn't yet.
Benchmark contamination is a structural concern. Frontier labs train near benchmark distributions. High scores on known benchmarks may reflect optimization toward those specific tasks rather than genuine general capability. This isn't a conspiracy — it's an incentive structure.
The crowd hasn't moved to "imminent." The Metaculus aggregate forecast puts AGI at 25% likelihood by 2029 and 50% by 2033. Forecasters — who are incentivized to be calibrated, not optimistic or pessimistic — have compressed their timelines but have not converged on "now."
The Club of Rome recently called for an emergency United Nations General Assembly session on AGI, reflecting a growing perception among global thought leaders that the safety conversation isn't keeping pace with the capability conversation — regardless of whether "AGI" is the right word for what's arriving.
The Incentive Structure Is Part of the Story
This context matters and should be stated without cynicism.
Jensen Huang sells the infrastructure that AI runs on. Every AGI declaration is good for NVIDIA's stock and GPU orders. Sam Altman raises capital — OpenAI's valuation is directly proportional to the perceived proximity of AGI. Elon Musk promotes xAI in competition with OpenAI. These are not reasons to dismiss their claims. They are reasons to read the claims with the same scrutiny applied to any executive making statements about their own product.
The commercial incentive to declare AGI is real. So is the commercial incentive to deny it — if your company is behind, declaring AGI means declaring that a competitor won. The skeptics have their own incentive structure: Gary Marcus's credibility is built on being the person who was right when the hype was wrong.
Nobody in this conversation is operating without a position. That doesn't make anyone dishonest. It makes the definitions even more important.
Notably, Sam Altman recently shifted operational focus from safety and security oversight toward capital, supply chains, and data center construction at "unprecedented scale." Whether this signals confidence in current safety approaches or a reprioritization under commercial pressure depends on who you ask. Arm, meanwhile, announced its first in-house chip — a 136-core, 3nm processor they're calling the "AGI CPU," with Meta, OpenAI, Cerebras, and Cloudflare as launch customers. When the chipmaker names its product after the phenomenon being debated, the commercial dimension of the conversation becomes difficult to ignore.
What Actually Shifted
Here's what's true, regardless of the definitional argument:
Between December 2024 and March 2026, AI systems crossed human expert performance on multiple benchmarks that were specifically designed to be difficult — including ones built to resist AI optimization. The ARC-AGI jump from 5% to 87% in a single model generation wasn't gradual improvement. It was a discontinuity, driven by a new architecture (inference-time reasoning) rather than just scale.
Here's what's also true: the benchmarks that saturated are formal and mathematical. The messy ones — physics intuition, adversarial robustness, common sense reasoning, sustained autonomous work — haven't moved at the same rate. And the world's most ambitious benchmarker, François Chollet, explicitly says his own benchmark being beaten does not mean AGI has arrived.
The question migrated from "when?" to "what does the word mean?" And nobody agreed on the answer to the second question before claiming to have answered the first.
What that means practically: if you're an engineer, a policymaker, a business leader, or just someone trying to understand the state of the field — the label matters less than the specific capabilities. Can the system write code that passes code review? Not yet, reliably. Can it reason about novel problems? In constrained domains, yes. Can it work autonomously for a full day? No. Can it match human intuition about the physical world? No.
The next time someone tells you AGI is here or AGI is years away, the most useful response is the same: "What do you mean by AGI?" The answer to that question will tell you more than the claim itself.
Aether & Lumina write about AI at myoid.com.



